
It's no surprise that people dislike it when things break. From shattered smartphones to malfunctioning appliances, the frustration is almost universal and quite obvious.
I'm no different. Not only do I dislike it when things break, but I also dislike when they don't work correctly all the time. Random hiccups and sudden white screens are the worst.
This started happening with my private server, which hosts this website and several personal projects and other websites. It's a bit messy, having been repurposed multiple times, but it should handle its tasks.
Except it wasn't.
Not long ago, I created a simple SPA presentation in React that cycles through random quotes from my colleagues, parodying famous inspirational cards. Instead of "Never give up," it shows "I hate C++" and so on, with beautiful background images to add to the absurdity. It was an all-nighter project (complete with a JSON-based database and an admin interface built with react-admin to add new quotes), but everyone loved it so it was worth it. We now have it constantly running on one of our office wall screens.
But one day, it stopped working. Only for a minute or so, not a big deal. Probably a network issue, right?
Then it started happening more frequently, sometimes multiple times per day. I looked into it, but I couldn't figure out what was going on. It's just a simple page that makes a request and shows some text, but the whole page was failing, not just the fetch request.
I thought it might be a problem with the PM2 service or Apache serving the app. I checked the logs but found nothing except Node complaining about some deprecated libraries.
I gave up for a while until it happened again while I was in the office. A colleague exclaimed that it wasn't working again, so I immediately tried to connect to the server via SSH to check what was going on.
But I couldn't connect. At first, I thought it was just a network problem, but everything else was working fine. So maybe the VPS provider was having connection issues?
In a last attempt to figure it out, I checked the OpenNebula administration of the VPS to see if the virtual machine was even on. It seemed fine, but when I connected through the embedded VNC in the administration, I was greeted with this beautiful image in the frame buffer:
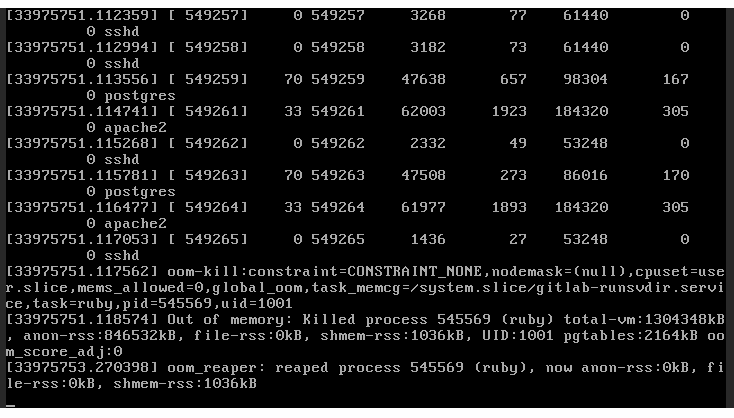
Yep, out of memory. That's why the whole server was unresponsive. Something was eating my memory like Santa eating cookies at Christmas, to the point where the OOM killer had to kick in and eliminate the Santa.
At least now I knew what was going on, and I even had a culprit: a service called gitlab-runsvdir. It's a GitLab service based on runit (a UNIX init scheme with service supervision) that ensures other services are running and automatically restarts them if they crash. It also manages the service directory (like the config files) and does other things, but I'm not an expert, so I won't pretend to know everything it does.
The point is, one shouldn't have to deal with this service. There's another gitlab-ctl process for the front-end, and usually, when you want to start, stop, or restart GitLab, you use that one. The gitlab-runsvdir service apparently starts at boot and should be left alone.
To be honest, I don't even know why I chose GitLab as my private DevOps platform. I just wanted something to push my personal projects to, and I don't even use 99% of the utilities GitLab provides. But we use GitLab at work, so I automatically installed it on my VPS too without considering alternatives. That was a mistake, because my VPS barely meets the minimum requirements (read: it doesn't).
It's crazy to me that I used to run a full private World of Warcraft server on my VPS without any problems, but it's not enough for GitLab?
Well anyway, I made some changes.
- I disabled clustered mode so that only a single Puma process would serve the application. I don't need concurrent connections; I'm literally the only user.
- I reduced the background processing daemon's concurrency mode. It's probably slower, but it doesn't allocate as much memory. I don't need lightning-fast speed.
- I reduced some memory and concurrency limits of the storage service.
- I disabled the monitoring service. I don't need to monitor myself.
- I reduced the size of memory chunks pre-allocated by GitLab to improve performance. Again, I can wait a few milliseconds more.
In the end, I pretty much just followed these recommendations: Running GitLab in a memory-constrained environment.
So far, so good. It's been several days without any crashes. I have to admit, though, even after the changes, GitLab is still a huge resource hog. About a quarter of my memory is used by it at all times, and another 20% is allocated and deallocated periodically:
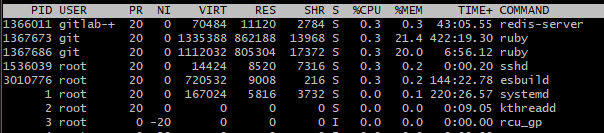
Maybe I should switch to Gitea, Forgejo, or something else. But I'm quite lazy and already committed to GitLab, so I guess for now, it can stay. I'll see where it goes in the future.

Add new comment